
자바스크립트 크롤러 만들기 튜토리얼 1편, 2편에서는 크롬 웹 브라우저에서 제공하는 [개발자 도구]를 이용하여 이미 열려 있는 웹페이지에서 원하는 정보를 찾는 방법을 알아보았습니다. 그런데 이 방식은 웹 브라우저를 실행한 후 사용자가 웹페이지를 직접 열고 [개발자 도구]에서 자바스크립트 코드를 입력해야 하므로 자동화가 쉽지 않습니다. (참고: ‘헤드리스 브라우저를 이용한 크롤링’에서 헤드리스headless 브라우저를 이용하여 UI 없는 웹 브라우저를 코드만으로 조작하는 방식으로 크롤링이 가능하긴 합니다)
웹 브라우저와 독립적으로 동작하는 CLIcommand line interface 기반 크롤러를 만들면 이 문제를 해결할 수 있습니다. CLI 애플리케이션으로 만들면 터미널terminal 또는 셸shell에서 쉽게 테스트해볼 수 있고, 서버에서 주기적으로 자동 실행되게 만들 수도 있습니다.
이 글에서는 노드JSNode.js 런타임을 이용하는 자바스크립트 코드로 크롤러를 작성한 후 터미널에서 해당 코드를 실행합니다. 자바스크립트로 크롤러를 작성하면 파이썬 등의 다른 언어로 크롤러 작성했을 때보다 몇가지 좋은 점이 있습니다.
- 자바스크립트에서는 웹페이지에서 데이터를 보관하거나 주고받는데 많이 사용되는 JSON 형식을 기본적으로 지원하기 때문에 사용이 매우 편리
- 데이터가 웹페이지의 자바스크립트 코드 안에 존재하는 경우 별다른 설정 없이 해당 코드를 읽어들여서 실행하는 것이 가능합니다. 이렇게 실행된 결과를 읽어들여서 원하는 데이터를 추출할 수 있습니다. (이런 경우 다른 언어로 크롤러를 만들면 자바스크립트 런타임 라이브러리를 설치해서 해결은 가능하지만 추가적인 작업이 필요해서 번거롭습니다.)
자 그럼 이제 노드JS 런타임을 이용하여 자바스크립트로 크롤러를 만드는 방법을 설명하겠습니다.
혹시 노드JS가 설치 되지 않으신 분들은 먼저 https://nodejs.org/ 에서 원하시는 버전을 다운로드 후에 설치해주세요. 여기서는 노드JS 16.15.0 버전 기준으로 설명을 진행합니다. 이 글에서는 node나 npm 명령어에 관한 자세한 설명은 생략합니다. 더 자세한 내용은 ‘코로나보드로 배우는 실전 웹 서비스 개발’ 책을 참고해 주세요.
개발 환경 설정
[crawler] 디렉터리를 만들어서 크롤러 개발 환경을 설정하겠습니다. 원하는 위치에서 다음 명령어를 수행해주세요.
$ mkdir crawler
$ cd crawler
$ npm init -y ❶
$ npm install axios@0.21.1 cheerio@1.0.0-rc.9 puppeteer@9.1.1 lodash@4.17.20 date-fns@2.21.1 date-fns-tz@1.1.4 ❷
❶에서 crawler 프로젝트를 초기화합니다. -y 옵션을 지정하면 초기화 시 기본값이 자동으로 입력되어 편리합니다.
❷는 크롤러를 만들 때 필요한 총 6개의 라이브러리를 설치하는 명령입니다. 각 라이브러리의 용도를 먼저 간단히 설명하면 다음과 같습니다.
axios: HTTP 호출을 더 편리하게 해주는 HTTP 클라이언트 라이브러리입니다. 이를 이용하여 웹 브라우저가 특정 URL로부터 웹페이지 HTML을 로드하듯이 크롤러에서도 특정 URL의 HTML을 로드할 수 있습니다.cheerio: 로드된 HTML을 파싱하여 DOM을 생성하는 라이브러리입니다. 웹 브라우저에서 제공하는 DOM 인터페이스와는 사용 방법이 좀 다르지만 구현된 기능 자체는 대부분 비슷해 CSS 셀렉터 문법을 사용한 검색이 가능합니다.puppeteer: 헤드리스 브라우저를 프로그래밍 방식으로 조작하는 라이브러리입니다.puppeteer설치와 함께 최신 버전의 크로미움Chromium이 자동으로 node_modules/puppeteer 경로 내부에 기본 설치됩니다.1lodash: 자바스크립가 기본 제공하지 않는 다양한 유틸리티 함수를 모아둔 라이브러리입니다.date-fns,date-fns-tz: 자바스크립트가 제공하는Date객체는 날짜/시간의 타임존 변환이나 원하는 날짜 형식으로 변환이 어렵습니다. 이를 해결해주는 라이브러리입니다.
첫 크롤러 만들어보기
이제 웹 브라우저가 아닌 노드JS 런타임을 이용하여 원하는 요소를 찾는 코드를 구현하겠습니다. 아래와 같이 코드를 작성한 후 node dom.js 명령어를 통해 실행하면 결과가 예제 페이지를 크롤링한 결과가 출력되는 것을 확인 할 수 있습니다.
crawler/examples/dom.js
const axios = require('axios');
const cheerio = require('cheerio');
async function main() {
// ❶ HTML 로드하기
const resp = await axios.get(
'https://yjiq150.github.io/coronaboard-crawling-sample/dom'
);
const $ = cheerio.load(resp.data); // ❷ HTML을 파싱하고 DOM 생성하기
const elements = $('.slide p'); // ❸ CSS 셀렉터로 원하는 요소 찾기
// ➍ 찾은 요소를 순회하면서 요소가 가진 텍스트를 출력하기
elements.each((idx, el) => {
// ❺ text() 메서드를 사용하기 위해 Node 객체인 el을 $로 감싸서 cheerio 객체로 변환
console.log($(el).text());
});
}
main();
[출력 결과]
국가별 내용
대한민국 내용❶ axios.get() 함수는 웹페이지에 HTTP GET 요청을 보내서 HTTP 응답을 받습니다. resp 객체의 data 필드를 통해서 응답받은 HTML 내용에 접근할 수 있습니다. HTML 응답 내용은 웹 브라우저로 열었을 때와 완전히 동일합니다.
노드JS 런타임은 웹 브라우저가 아니므로 해당 HTML 내용을 자동으로 파싱하여 DOM을 만들어주지는 못합니다. 그래서 ❷ cheerio 라이브러리를 이용하여 DOM을 만들어줍니다. cheerio.load()를 통해 DOM을 구성한 후 cheerio 객체 형태로 반환해줍니다. 이렇게 반환된 cheerio 객체는 내부에 DOM 정보를 모두 가지고 있습니다. 생성된 cheerio 객체는 관행적으로 $ 변수에 저장해 사용합니다. 이렇게 변수 이름을 지정하면 ❸ CSS 셀렉터로 원하는 요소를 찾을 때도 $('.slide p') 형식으로 호출할 수 있어 편리합니다. 이러한 형식으로 요소를 찾는 방식은 jQuery2에서부터 사용하는 오래된 관습입니다.
❹에서는 ❸에서 찾은 요소를 cheerio 객체에서 제공하는 each() 함수를 사용해 순회하면서 해당 요소의 내용을 출력합니다. 이때 ❺에서처럼 특정 요소를 나타내는 el 변수를 직접 사용하지 않고 $(el) 형태로 감싸서 사용합니다. 이렇게 하는 이유는 뭘까요?
el 변수에 담긴 요소는 cheerio에서 만들어낸 DOM 상의 Node 객체3입니다. 이 Node 객체는 순수하게 DOM 상의 Node를 표현하는 기능만 갖고 있습니다(웹브라우저에서 DOM을 다룰 때 존재하는 Node 객체와 기본적인 개념은 동일하지만 제공되는 기능에 차이가 있습니다).
때문에 단순히 Node 객체만 가지고는 해당 Node와 자식 Node가 가진 텍스트 내용만 손쉽게 추출할 방법이 없습니다. 하지만 이 Node 객체를 cheerio 객체4로 한 번 감싸주면 cheerio에서 제공하는 추가 기능을 사용할 수 있게 됩니다. 위 예시에서 Node와 그 자식 Node가 가진 텍스트 내용만 추출하는 데 사용한 text() 함수가 바로 cheerio에서 제공되는 기능입니다(이러한 패턴 또한 앞서 언급한 jQuery에서 사용하던 코드 관습을 그대로 옮겨온 겁니다).
![[그림 4-12] cheerio 객체를 만들어서 사용하는 방법](/uploads/2022/05/4-12_cheerio_wrapper-1024x773.png)
cheerio 기본 사용법
cheerio를 이용하여 CSS 셀렉터 조건에 맞는 요소들을 찾아 순회하거나, 찾은 요소 중에 특정 요소를 선택하는 등의 처리를 하게 됩니다. 위 예시에서는 each() 함수를 사용했는데 이 함수 외에 자주 사용하는 함수를 소개하겠습니다. 아래 예제 코드 또한 위에서 사용한 동일한 예제 웹페이지에 대해 수행합니다.
each(): 찾은 요소들을 단순히 순회합니다.map(): 찾은 요소들을 순회하면서 각 요소에서 얻은 값을 이용하여 데이터를 추출하고 변환하여, 반환값들을 모아둔 배열을 만들 수 있습니다. cheerio 객체 내부에서 사용하는 배열을 자바스크립트 배열로 변환하는 데toArray()함수를 사용합니다.
const textArray = $('.slide p')
.map((idx, el) => {
return $(el).text();
})
.toArray();
// textArray에 저장된 값: ['국가별 내용', '대한민국 내용']
find(): 찾은 요소를 기준으로 새로운 조건을 적용하여 검색합니다. 어떤식으로 사용하는지 설명하기 위해 ❶ 두 단계에 걸쳐서 검색을 진행했습니다만,$('.container h1')처럼 한 번에 검색할 수도 있습니다.
$('.container')
.find('h1')
.each((idx, el) => {
console.log($(el).text());
});
// 출력값: '코로나보드'
next(),prev(): 찾은 요소를 기준으로 인접한 다음 또는 이전 요소를 찾습니다.
const nextElement = $('#country-title').next();
// nextElement.text()의 값: '국가별 내용'
const prevElement= $('#country-title').prev();
// prevElement.text()의 값: ''
first(),last(): 찾은 요소 중 첫 번째 요소 또는 마지막 요소를 찾습니다.
$('.slide p').first().text(); // 국가별 내용
$('.slide p').last().text(); // 대한민국 내용
이 외에도 다양한 기능을 제공합니다. 궁금하신 분은 cheerio 레퍼런스 문서를 참고하세요.5
웹페이지 유형별 크롤링 방식 결정 방법
웹페이지에서 데이터를 불러와서 사용자에게 보여주는 방식은 다양하지만 결국 웹페이지를 구성하는 DOM안의 특정 요소에 데이터가 있다는 사실은 변하지 않습니다. 따라서 웹페이지 크롤러를 만드는 첫 번째 과정은 크롤링하고자 하는 데이터의 위치를 파악하는 겁니다. 웹페이지를 구성하는 요소 중 우리가 찾는 데이터가 존재할 만한 곳은 다음과 같이 세 곳입니다.
- 웹페이지 최초로 불러오는 HTML(메인 HTML 소스)
- API 호출을 통해서 외부에서 데이터를 불러오는 경우 해당 API의 응답
- HTML을 통해서 로드된 자바스크립트 파일 내부(데이터가 코드 형태로 하드코딩되어 있을 수 있음)
데이터 위치에 따라서 추출 방법이 달라지기 때문에 크롤러를 작성하기 전에는 해당 데이터가 어디에 위치하는지를 크롬 [개발자 도구]에서 반드시 확인해야 합니다. (크롬 개발자 도구를 사용하는 방법은 2편을 참고 바랍니다.)
[그림 4-13]는 데이터 위치에 따른 크롤링 방법을 결정하는 순서를 그림으로 보여줍니다. 전체적인 흐름을 먼저 이 그림에서 살펴본 후 각 단계의 조건을 자세히 설명하겠습니다.
![[그림 4-13] 크롤링 방식 의사 결정 트리](/uploads/2022/05/4-13_crawling_method_decision_tree-1024x797.png)
메인 HTML 소스에 찾는 데이터가 존재하는 경우(1, 2번)
웹페이지에서 최초로 불러오는 HTML 소스에서 데이터가 존재하는지 확인하는 방법을 알아봅시다. 해당 페이지를 웹 브라우저에서 열어둔 상태로 ➝ 마우스 오른쪽 버튼을 클릭하여 ➝ [페이지 소스 보기]를 선택합니다. 그러면 새로운 창이 열리면서 웹페이지에서 최초로 불러오는 HTML 소스가 나타납니다.
주의: 크롬 [개발자 도구]의 Elements 탭에 나오는 HTML은 자바스크립트 등에 의해 동적으로 변경된 ‘현재 상태’를 보여주기 때문에 ‘페이지 소스 보기’에서 나오는 HTML의 내용은 다를 수도 있습니다.
정적인 웹페이지라면 HTML 내용 안에 원하는 데이터가 존재할 가능성이 매우 큽니다. 두 가지 방식으로 데이터가 존재할 수 있습니다.
첫 번째는 HTML 태그 안에 텍스트 형태로 존재하는 경우입니다. 웹페이지 주소에서 HTML을 불러온 후 cheerio를 이용해 요소를 찾아내는 방식을 사용하면 됩니다. 이 방식이 가장 기본적이기도 하고 가장 많은 웹페이지에 적용되는 방식입니다. 첫 크롤러를 만들 때 사용한 방식이기도 합니다.
두 번째는 ❶ script 태그 안에 자바스크립트 코드로 데이터가 하드코딩된 경우입니다. script 태그 안에 자바스크립트 코드를 인라인inline으로 작성하면 페이지가 로드되면서 자동으로 실행됩니다. 이곳에 변수를 선언해 자바스크립트 코드 형태로 원하는 데이터를 하드코딩해두면, 언제든 해당 변수에 접근해 데이터를 읽을 수 있습니다. 예를 들어 다음과 같은 페이지에서 ‘크롤링할 내용’ 텍스트를 추출하려면 어떻게 해야 하는지 알아보도록 합시다.
https://yjiq150.github.io/coronaboard-crawling-sample/dom-with-script
<html>
... 생략 ...
<body>
... 생략 ...
<script>
var dataExample = { title: '제목', content: '크롤링할 내용' };
</script>
</body>
</html>가장 쉽고 효율적인 방법은 script 태그에 있는 자바스크립트 소스 코드를 노드 환경에서 실제로 실행한 후 해당 변수의 값을 읽어들이는 겁니다. 예제 코드를 보면서 하나씩 설명하겠습니다.
crawler/examples/dom-with-script.js
const axios = require('axios');
const cheerio = require('cheerio');
// ❶ 추출된 자바스크립트 코드를 별도 실행하는 가상 환경 기능 로드
const vm = require('vm');
async function main() {
const resp = await axios.get(
'https://yjiq150.github.io/coronaboard-crawling-sample/dom-with-script',
);
const $ = cheerio.load(resp.data);
// ❷ script 태그를 찾아서 코드 추출
const extractedCode = $('script').first().html();
// ❸ 컨텍스트를 생성 후 해당 컨텍스트에서 추출된 코드 실행
const context = {};
vm.createContext(context);
vm.runInContext(extractedCode, context);
// ➍ 스크립트 내에 하드코딩된 정보에 접근
console.log(context.dataExample.content);
}
main();
[출력 결과]
크롤링할 내용노드JS에서는 외부에서 불러온 자바스크립트 코드를 실행하는 기능을 제공합니다. 바로 vm 기능입니다. 기본 내장 라이브러리에서 제공되는 기능이라서 ❶에서처럼 곧바로 사용이 가능합니다.
❷ HTML 태그 안의 텍스트를 추출하던 방식으로 script 태그를 찾고, script 태그 안에 존재하는 코드를 추출합니다. 특정 요소 서브에 속한 모든 텍스트만 추출하는 경우에는 text() 함수를 사용하지만 여기에서는 원본 HTML에서 script 태그 안에 작성된 내용 그 자체를 가져오기 위해서 html() 함수를 호출했습니다.
❸ 새롭게 컨텍스트context를 만들어 추출된 코드를 실행합니다. 여기서 컨텍스트란 코드가 실행되면서 생성한 변수나 값들이 저장되는 공간이라고 생각하시면 됩니다. 실행된 코드에서 사용한 변수들은 해당 컨텍스트 안에서만 생성되고 존재합니다. 코드가 실행되면 dataExample 변수가 컨텍스트 내에 생성되어, 컨텍스트 객체를 통해서 접근할 수 있습니다. ❹ dataExample 변수를 이용하여 목표로 한 ‘크롤링할 내용’을 추출합니다.
API를 호출해서 외부에서 데이터를 불러오는 경우(3번)
웹 브라우저로 웹페이지를 불러올 때는 분명히 찾는 데이터가 있는데 HTML 소스 보기를 하면 없는 경우도 자주 있습니다. 보통 웹페이지 어딘가에서 API를 호출을 추가로 데이터를 불러오기 때문일 가능성이 높습니다.
메인 HTML 내부에 기본 콘텐츠가 있고 일부 데이터는 동적으로 불러오는 형태로 설계된 웹사이트들 이에 해당합니다. 웹페이지에서 사용하는 API는 일반적으로 HTTP 기반의 API를 많이 사용하므로 이런 API 호출이 일어났는지부터 확인해야 합니다. 이때 크롬 [개발자 도구]의 [Network] 탭이 아주 유용합니다.
[Network] 탭을 실제로 어떤식으로 사용하는지 잘 보여줄 예제 페이지를 준비해두었습니다.
이 페이지를 웹 브라우저에서 열면 웹 브라우저 화면에 다음과 같이 페이지가 렌더링됩니다. 이 중 ‘API 호출로 받아온 내용입니다’라는 부분을 크롤러를 만들어서 추출하고 싶다고 가정해봅시다.

이제 [개발자 도구]를 열고 ➝ [Network] 탭에서 ➝ 레코딩이 활성화된 상태로 ➝ 페이지를 새로고침하고 ➝ ❶ All을 선택하면 ➝ 해당 페이지에서 주고받은 모든 통신 내용이 기록됩니다. 예제 웹페이지에서는 다음과 같이 ❷ 요청이 2번 발생했음을 확인할 수 있습니다.
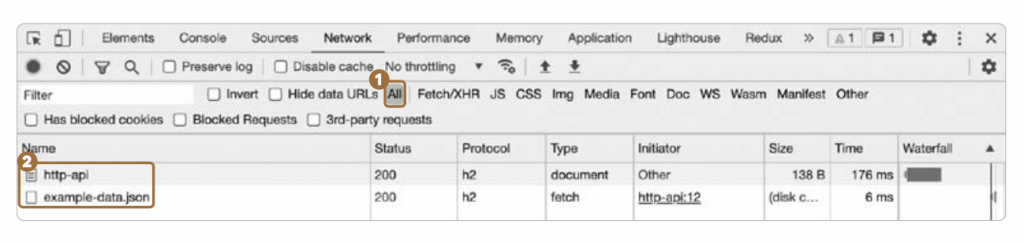
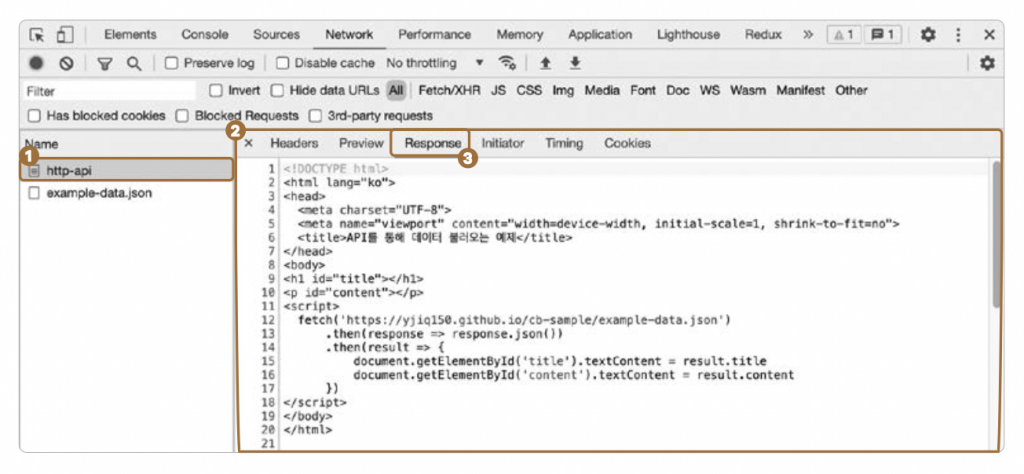
http-api는 예제 웹페이지의 HTML을 불러오는 요청입니다. [Protocol]6 값이 h2인데, HTTP/2 프로토콜을 사용해서 통신을 진행했다는 말입니다. [Type]은 document입니다. HTML과 같은 웹페이지 불러왔다는 의미입니다. ❶ [Name]에서 http-api를 클릭하면 ➝ ❷ 오른쪽에 나오는 패널이 나타나면서 ➝ ❸ [Response] 탭에 HTML 내용을 보여줍니다([페이지 소스 보기] 기능을 사용했을 때 나타나는 내용과 동일합니다).
웹 브라우저에서 접속했을 때 분명히 ‘API 호출로 받아온 내용입니다’라는 글자를 확인할 수 있죠. 그런데 코드를 보면 h1, p 태그의 내용이 모두 비어 있고 해당 문구가 안 보이네요. 그렇다면 해당 문구는 도대체 어디서 나타난 걸까요? 다음 코드를 살펴보겠습니다.
https://yjiq150.github.io/coronaboard-crawling-sample/http-api
<html lang="ko">
... 생략 ...
<body>
<h1 id="title"></h1>
<p id="content"></p>
<script>
// ❶ fetch() 함수를 이용해 아래 URL에서 json 형태로 데이터 불러오기
fetch('https://yjiq150.github.io/coronaboard-crawling-sample/example-data.json')
.then(response => response.json())
.then(result => {
document.getElementById('title').textContent = result.title
document.getElementById('content').textContent = result.content
})
</script>
</body>
</html>❶ fetch() 함수를 이용하여 특정 주소에 요청을 하여 json 형식으로 작성된 텍스트 응답을 받습니다. 이 응답 내용을 json 함수를 사용해 자바스크립트 객체로 변환한 후 ➝ 해당 객체에 담긴 title, content 필드값 각각을 h1 태그와 p 태그에 넣어준 겁니다. 이 코드를 보면 해당 문구가 https://yjiq150.github.io/coronaboard-crawling-sample/example-data.json 주소에 대한 응답에 있다는 사실을 유추할 수 있습니다.
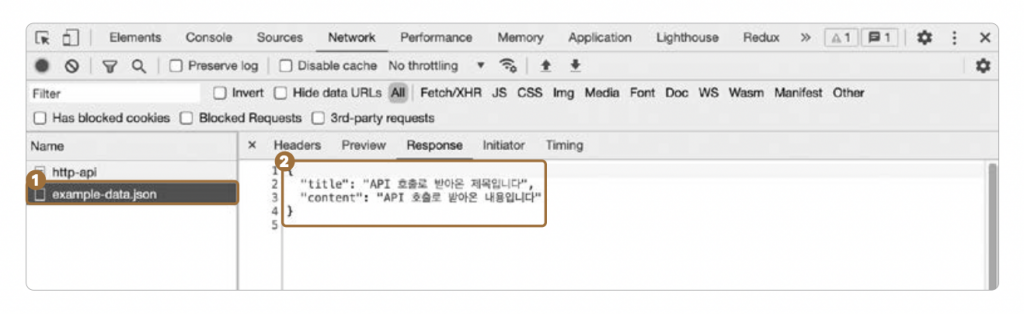
데이터를 받아오는지 알아내는 다른 방법으로는 [Network] 탭에 기록된 요청을 살펴보는 방법이 있습니다. [Network] 탭에 기록된 ❶ example-data.json을 클릭하여 응답 내용을 확인하면 ❷ 웹 브라우저 표시된 문구들을 확인할 수 있습니다.
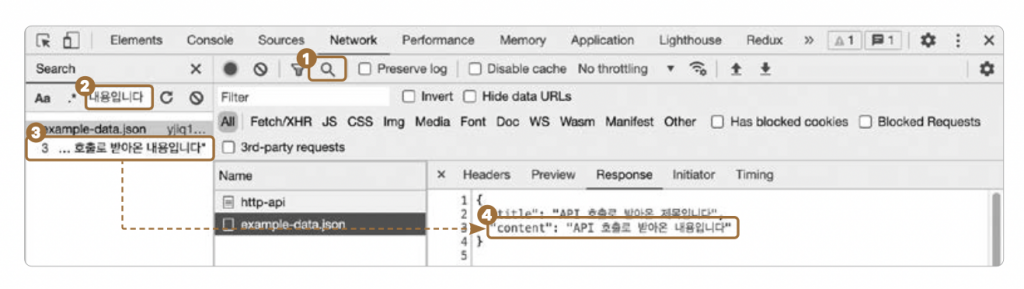
네트워크 요청이 적으면 손쉽게 찾을 수 있지만 페이지가 복잡하여 수십 개 요청이 수행되거나 응답 데이터양이 너무 많은 경우 눈으로 훑어보기가 어렵습니다. 이때는 [Network] 탭 설명을 하던 도중 언급한 ‘응답 본문 검색’ 기능을 사용하면 됩니다. 다음처럼 ❶ 돋보기 아이콘을 눌러서 좌측 검색 패널을 활성화한 후 ➝ ❷ 검색 키워드(예를 들어 ‘API 호출로 받아온 내용입니다’)를 검색 ➝ ❸ 검색된 내용을 클릭하면 ➝ ➍ 해당 응답이 열리면서 해당 위치를 하이라이트까지 해줍니다.
데이터가 있는 API 경로를 찾아냈으니 크롤링 코드를 작성해봅시다.
crawler/examples/http-api.js
const axios = require('axios');
async function main() {
const resp = await axios.get(
'https://yjiq150.github.io/coronaboard-crawling-sample/example-data.json',
);
console.log(resp.data.content);
}
main();
[출력 결과]
API 호출로 받아온 내용입니다API 주소에서 데이터를 바로 가져와서 사용할 수 있어서 HTML에서 정보를 찾아낼 때보다 훨씬 코드가 간단합니다.
참고로 axios에서는 응답 헤더의 Content-Type이 application/json이면 응답 내용이 JSON인 것을 인식하고 텍스트로 받은 응답을 자동으로 자바스크립트 객체로 만듭니다(웹 브라우저를 이용하는 예제에서는 수동으로 진행해줘야 했죠). 그래서 응답 객체의 data 필드에 접근하면 이미 객체화된 데이터에 바로 접근할 수 있습니다.
웹사이트에서 HTTP API로 데이터를 불러올 때 ‘데이터 자체’만을 포함한 JSON 형식을 주로 사용합니다. 하지만 가끔 데이터 외에 해당 데이터를 둘러싼 태그까지 포함된 HTML 형태로 데이터를 불러오는 경우도 있습니다. 이때는 html 태그, body 태그 등 기본적인 HTML을 구성하는 태그가 없습니다. 실제 사용자에게 보여줄 데이터와 태그가 포함된 HTML을 메인 HTML에 끼워넣는 방식으로 사용자에게 보여주게 됩니다. 이러한 데이터를 크롤링하는 방법은 메인 HTML을 cheerio를 통해 파싱해서 원하는 데이터를 찾는 방법과 동일하기 때문에 자세한 설명은 생략하겠습니다.
그래도 데이터가 안 나온다면?
지금까지 설명한 방법들만 잘 이용해도 대부분의 웹사이트를 크롤링할 수 있습니다. 앞서 설명한 모든 방법을 다 썼는데도 눈에 보이는 데이터를 찾지 못했다면 다음과같은 경우일 수 있습니다.
첫 번째는 데이터가 자바스크립트 코드 내에 존재하지만 해당 데이터에 접근하는 명확한 경로를 알 수 없는 경우입니다. 앞서 예제에서는 HTML 안에 존재하는 script 태그 안에 인라인으로 자바스크립트 코드를 작성하고 전역 변수를 사용했기 때문에 데이터 접근이 쉬웠습니다. 하지만 실제 규모 있는 웹페이지에서는 script 태그에서 별도의 자바스크립트 파일을 읽어들여서 실행하는 방식을 더 많이 사용합니다. 이때에도 전역 변수가 사용된다면 해당 자바스크립트 파일의 코드를 vm 라이브러리를 통해 실행한 후 전역 변수에 접근하여 사용하면 됩니다. 반면 전역 변수가 아니라 자바스크립트 파일 깊숙한 곳에 존재하는 변수라면 접근이 어렵습니다.
두 번째는 보안을 강화할 목적으로 데이터를 암호화/인코딩encoding해서 전달을 하는 경우입니다. 이 경우에는 [Network] 탭에서 원하는 텍스트를 검색하더라도, 데이터가 평문이 아니기 때문에 검색되지 않습니다. 이런 경우에는 해당 페이지에서 사용하는 자바스크립트에 포함된 관련 코드를 분석하여 주고받는 데이터를 복호화/디코딩decoding해야 합니다.
위 두 가지 경우에는 결국 실제로 웹브라우저로 해당 웹페이지를 열고, 웹페이지의 렌더링이 완료되기를 기다린 후 웹브라우저에 로드된 DOM에서 원하는 데이터를 찾아서 추출해야 합니다 (4번 방식). 이 방식은 접근 방법 자체가 다르므로 다음 절에서 알아보겠습니다.
마지막으로 HTTP API 통신이 아닌 웹소켓WebSocket 등을 이용한 소켓 통신 방식으로 데이터를 주고받는 경우가 있을 수 있습니다. 다행히 웹소켓 통신 내용은 [개발자 도구]의 [Network] 탭에 잘 나타나기 때문에 데이터의 존재 여부 확인은 쉽습니다. 이 경우 크롤링하고자 하는 웹소켓 통신의 요청/응답 내용을 잘 분석하여 어떤 식으로 데이터를 주고받는지를 정확히 파악해야 합니다. 그 후 원하는 데이터를 서버에 요청하면 응답으로 해당 데이터를 받게 되고, 이 응답에서 원하는 데이터를 추출하는 식으로 크롤러를 구현하면 됩니다).
헤드리스 브라우저를 이용한 크롤링 (4번)
헤드리스 브라우저headless browser란 GUI 없이 CLI에서 실행되는 웹 브라우저입니다. 예를 들어 구글 크롬은 헤드리스 모드를 제공합니다. 헤드리스 브라우저를 사용하면 CLI 환경에서 웹페이지의 스크린샷을 생성한다든가, 해당 웹페이지의 특정 버튼을 눌러서 의도한 대로 동작이 잘 되는지 테스트를 해본다든가 하는 자동화 작업을 편리하게 할 수 있습니다. 특히 크롬 개발팀에서 만든 puppeteer 라이브러리를 사용하면 크롬 브라우저의 모든 기능을 제어할 수 있습니다. 때문에 브라우저에 페이지가 완전히 로드되기를 기다렸다가 완성된 DOM에서 원하는 데이터를 찾으면 됩니다. 이 방식을 사용하면 데이터가 어디에 존재하는지 일일이 네트워크 요청을 뒤질 필요가 없습니다. 일반 웹 브라우저에서 사용자가 보는 웹페이지에 우리가 찾는 데이터가 있다면 헤드리스 브라우저에서도 우리가 찾는 데이터가 동일한 위치에 존재할 것이기 때문입니다.
예시를 보면서 어떤식으로 동작하는지 확인합시다.
헤드리스 브라우저로 크롤링하기
헤드리스 브라우저로 크롤링할 예시 페이지 주소는 다음과 같습니다.
먼저 일반 웹 브라우저에서 페이지를 열고 어떻게 동작하는지 확인을 해봅시다. 페이지를 열면 [제목/내용] 불러오기 버튼만 덩그러니 있고 아무런 데이터가 없습니다. 해당 버튼을 클릭하면 페이지의 제목과 내용을 불러와서 보여줍니다. 크롤링하길 원하는 데이터가 ‘API 호출로 받아온 내용입니다’라고 가정하고 설명을 진행하겠습니다([Network] 탭에서 쉽게 확인할 수 있습니다).
crawler/example/headless-browser.js
const puppeteer = require('puppeteer');
async function main() {
const browser = await puppeteer.launch(); // ❶ 헤드리스 브라우저 실행
const page = await browser.newPage(); // ❷ 브라우저에 새 페이지 생성
const pageUrl = 'https://yjiq150.github.io/coronaboard-crawling-sample/http-api-with-button';
await page.goto(pageUrl, {
// ❸ 모든 네트워크 연결이 500ms 이상 유휴 상태가 될 때까지 기다림
waitUntil: 'networkidle0',
});
// ➍ 제목/내용 불러오기 버튼을 클릭
await page.click('input[type="button"]');
await page.waitForFunction(() => {
// ➎ 함수가 웹브라우저의 컨텍스트에서 실행되기 때문에 document 객체에 접근 가능
return document.getElementById('content').textContent.length > 0;
});
// ➏ 특정 셀렉터에 대해 제공된 함수를 수행한 값 반환
const content = await page.$eval(
'#content',
(elements) => elements[0].textContent,
);
console.log(content);
await browser.close(); // ➐ 작업이 완료되면 브라우저 종료
}
main();
[출력 결과]
API 호출로 받아온 내용입니다❶ 헤드리스 브라우저를 실행합니다. launch() 함수에 인수를 넣지 않아 기본 설치된 크로미움이 실행됩니다.
실행된 웹 브라우저는 헤드리스 모드이기 때문에 눈에 보이지는 않지만 pupeeteer에서 제공하는 함수를 이용해 제어할 수 있습니다. ❷ 새로운 페이지를 생성합니다. 페이지가 준비되면 page 객체에서 제공하는 goto() 함수를 이용하여 특정 주소를 로드합니다.
❸ waitUntil 옵션을 주면 해당 주소에 대한 웹페이지 로드 코드를 수행한 후 다음 코드를 실행하기 전에 언제나 기다릴지를 정할 수 있습니다. 아래처럼 여러 옵션을 지원하므로 용도에 맞게 사용하면 됩니다.
domcontentloaded: 메인 HTML이 로드되어 DOM이 생성된 순간까지 기다립니다. 포함된 리소스의 로드는 기다리지 않기 때문에 찾는 내용이 메인 HTML 자체에 존재하는 경우 유용합니다.load: 메인 HTML과 포함된 자바스크립트, CSS, 이미지 등 모든 리소스가 로드될 때까지 기다립니다.networkidle0: 최소 500ms 동안 활성화된 네트워크 연결이 완전히 없어질 때까지 기다립니다. 자바스크립트를 사용한 API 요청이 있는 페이지에 유용합니다.networkidle2: 최소 500ms 동안 활성화된 네트워크 연결이 2개 이하로 유지될 때까지 기다립니다. 웹페이지 로드가 완료된 이후에도 주기적으로 정보를 업데이트하는 등 폴링 방식으로 구현된 웹페이지에 적용하면 유용합니다.
용어: 폴링(polling)
외부 상태를 확인할 목적으로 주기적으로 검사를 수행하는 방식. 클라이언트/서버 환경에 적용하면 보통 클라이언트가 서버에 주기적으로 요청을 해서 새로운 정보가 있는지 확인하여 받아오는 방식을 의미합니다.
앞서 예제 페이지를 직접 열어보면 [제목/내용 불러오기] 버튼을 누르기 전까지는 원하는 데이터가 페이지에 렌더링되어 있지 않기 때문에 크롤링할 방법이 없습니다. 그래서 ❹ page 객체에서 제공하는 click() 함수를 이용하여 원하는 요소를 CSS 셀렉터로 지정하고, 선택된 요소에 클릭 이벤트를 발생시켜서 웹 브라우저에서 클릭한 효과를 만들어줍니다.
이때 API가 호출되고 데이터를 불러오는 과정에 시간이 걸립니다. 데이터를 불러와서 해당 내용이 DOM을 업데이트되기 전까지는 원하는 데이터를 얻을 수 없습니다. page 객체는 작업이 완료될 때까지 기다리는 다음과 같은 여러 함수를 제공합니다.
waitForTimeout: 단순히 지정한 시간만큼 기다리는 함수입니다. 네트워크 속도나 상황에 따라 응답 속도가 달라질 수 있어서 상황에 맞게 2초에서 30초로 잡게 됩니다. 대기 시간이 길면 크롤링 시간도 그만큼 오래 걸려서 비효율적입니다. 최대한 사용을 지양하는 것이 좋습니다.waitForFunction: 조건을 인수로 받아, 실제 웹 브라우저 컨텍스트에서 실행을 하여 참이 될 때까지 기다리는 함수입니다. 웹 브라우저 컨텍스트에서 실행되기 때문에 웹 브라우저에 전역 객체로 존재하는document객체에 접근을 하여 사용합니다. ❺ id값이 content인 요소에 접근하여 텍스트가 채워져 있는지를 확인합니다.waitForSelector: CSS 셀렉터를 인수로 받고, 해당 셀렉터를 만족하는 요소가 존재할 때까지 기다리는 함수입니다.waitForFunction보다 간편하게 사용할 수 있지만 요소의 존재 여부로만 판단하기 때문에 복잡한 조건에서는 사용이 불가능합니다.
웹 브라우저에서 버튼을 클릭하고 API 응답을 받아 페이지에 콘텐츠가 채워지는 시점까지 기다리는 데 성공했습니다. 마지막으로 웹 브라우저에 로드된 DOM의 특정 요소에 접근하여 값을 가져올 일만 남았습니다. 이 작업은 이미 웹 브라우저의 콘솔에서 수동으로 코드를 입력하여 실행하는 방식으로 한번 다룬 내용입니다 (튜토리얼 2편 참고). 여기서는 puppeteer를 이용해서 노드 환경에서 동작하는 자바스크립트 코드로 작성하여 자동화하겠습니다.
❻에서처럼 page 객체에 존재하는 $eval() 함수를 사용하면 웹 브라우저 컨텍스트에서 코드를 실행하고, 반환값을 가져올 수 있습니다. id값이 content 인 요소를 찾고, 찾은 요소의 textContext 속성에 접근하여 가져온 값을 반환합니다. 반환된 값은 최종적으로 content 변수에 저장됩니다. 그 결과 ‘API 호출로 받아온 내용입니다’가 잘 출력됩니다.
❼ 크롤링이 완료되었으니 헤드리스 웹 브라우저를 종료합니다. 웹 브라우저는 메모리를 상당히 많이 사용하는 애플리케이션이기 때문에 꼭 종료해주는 것이 좋습니다.
puppeteer에 대한 더 자세한 소개는 다음 사이트에서 확인하기 바랍니다.
질문: 모든 크롤러를 헤드리스 브라우저로 만들면 안 되나요?
모든 크롤러는 헤드리스 브라우저로 만들 수 있습니다. 헤드리스 브라우저 기반으로 크롤러를 만들면 UI가 있는 웹 브라우저를 사용할 때보다는 메모리를 약간 적게 사용합니다. 하지만 여전히 크롤러가 시작될 때 헤드리스 웹 브라우저 애플리케이션도 같이 실행되어야 합니다. 크롤러만 사용할 때보다 시작 속도도 느리고 메모리도 많이 사용하죠. 때문에 크롤링을 할 때 가능하면 헤드리스 브라우저를 쓰지 않는 것이 더 빠르고 효율적입니다.
마무리
이제 다양한 유형의 웹사이트를 크롤링하기 위한 기본적인 방법을 모두 익혔습니다. 이정도까지만 익혀둬도 왠만한 웹페이지는 손쉽게 크롤링 하실 수 있을 것입니다. 조금 더 응용력을 길러드리기 위해서 4편에서는 복잡한 웹페이지를 실제로 크롤링해서 원하는 데이터를 추출하는 것을 실습해보도록 하겠습니다.
- 자바스크립트로 크롤러 만들기 소개: 크롤링 개념 및 튜토리얼 소개
- 자바스크립트로 크롤러 만들기 1편: 크롤링을 위한 크롬 개발자 도구 사용법 익히기
- 자바스크립트로 크롤러 만들기 2편: 웹페이지 크롤링을 위한 배경 지식 알아보기
- 자바스크립트로 크롤러 만들기 3편: 다양한 유형의 웹페이지 크롤러 만들어보기
- 자바스크립트로 크롤러 만들기 4편: 실제 웹페이지 크롤링해보기

‘코로나보드로 배우는 실전 웹 서비스 개발’ 책에서는 크롤러 뿐만 아니라 구글 스프레드 시트를 저장소로 사용하는 방법, 개츠비 + 리액트를 사용해서 웹사이트를 개발하는 방법, 도메인 설정, 검색엔진 최적화, 사용자 분석, 광고를 통한 수익화 등을 다룹니다. 웹서비스 개발과 운영에 대한 전반적인 내용을 알고싶으신 분들이나, 사이드 프로젝트를 만들어보고 싶으신 분들에게 추천합니다.
각주
- 크로미움은 크롬의 기반이되는 오픈소스 웹 브라우저 프로젝트입니다. 기본적인 웹브라우징 기능은 동일하기 때문에 크롤러를 만드는 데 문제가 없습니다. ↩
- 유저 인터랙션이 별로 없는 웹 사이트에 여전히 많이 사용됩니다. ↩
- https://cheerio.js.org/classes/Node.html ↩
- https://cheerio.js.org/classes/Cheerio.html ↩
- cheerio 레퍼런스 문서 : https://cheerio.js.org/classes/cheerio.html ↩
- 이 컬럼이 보이지 않는 경우 컬럼 표시줄에 오른쪽 버튼을 클릭해서 원하는 컬럼을 추가 선택할 수 있습니다. ↩