
1,2,3편에서 배운 지식들을 이용하여 이번편에서는 실제 웹사이트를 크롤링해서 데이터를 추출하는 것을 실습할 차례입니다. 드디어 마지막 편입니다. 조금만 힘내서 자바스크립트로 크롤링하는 기술을 마스터 해봅시다!
크롤링할 사이트 소개
코로나보드의 데이터는 질병관리청에서 운영하는 코로나19 웹사이트로부터 크롤링을 합니다. 이렇게 실제 웹페이지에 맞춰서 크롤러를 만들어 두면 만든 직후에는 잘 동작하지만, 해당 사이트의 구성이나 디자인이 업데이트되는 순간 웹페이지 내의 데이터 위치도 같이 바뀌기 때문에 기존 크롤러 코드가 제대로 동작을 하지 않을 가능성이 큽니다. 때문에 크롤러의 코드는 지속적인 유지보수가 필요합니다. 이 책에서는 이러한 유지보수를 피하고 설명의 일관성을 유지하고자 실제 크롤링할 웹페이지 전체를 클론해서 학습용으로 제공합니다 .
- 질병관리청 코로나191 클론 사이트 :
https://yjiq150.github.io/coronaboard-crawling-sample/clone/ncov/ - 월드오미터2 클론 사이트 : https://yjiq150.github.io/coronaboard-crawling-sample/clone/worldometer/
질병관리청 코로나19 사이트에서는 국내 데이터, 월드오미터에서는 해외 데이터를 얻을 수 있습니다.
참고: 코로나보드로 배우는 실전 웹 서비스 개발 책에서는 월드오미터 웹사이트까지 크롤링하는 내용을 다루지만, 이 글에서는 질병관리청의 코로나19 웹사이트를 크롤링하는 부분만 다루도록 하겠습니다.
코로나19 국내 통계 크롤링하기
코로나19 관련 국내 통계들을 질병관리청 코로나19 클론 사이트로부터 크롤링하겠습니다. 크롤링할 항목은 다음과 같습니다.
- 확진자, 사망자, 격리해제, 검사중, 결과음성, 총 검사자 수
- 성별에 따른 확진자, 사망자 수
- 연령에 따른 확진자, 사망자 수
크롬 [개발자 도구]에서 페이지를 살펴보면 우리가 크롤링하고자 하는 데이터 항목들이 모두 메인 HTML 소스에 존재합니다. 즉, 튜토리얼 3편에서 다뤘던 웹페이지 유형 중 1번 유형입니다. 이제 유형을 파악했으니 HTML 소스로부터 데이터를 추출하는 크롤러를 만듭시다.
이번에 만들 크롤러 구성은 다음과 같습니다.
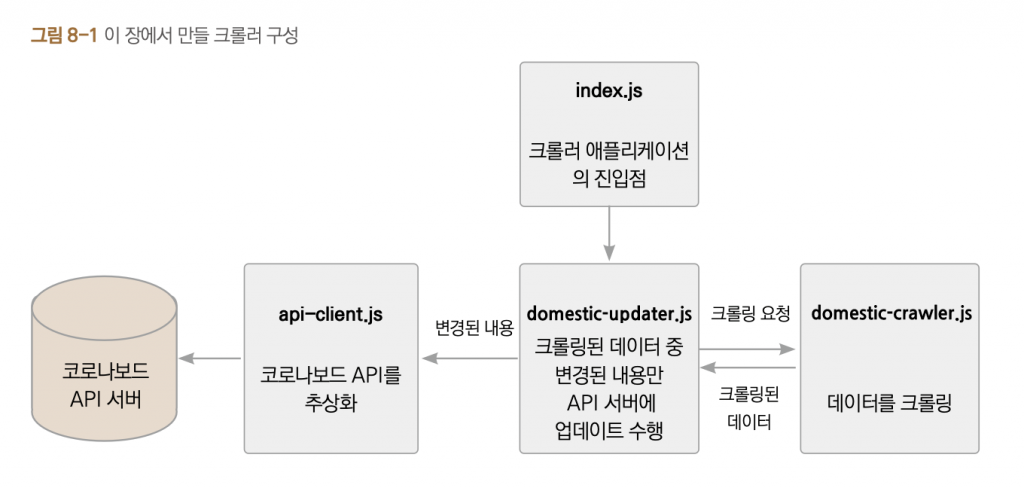
코로나보드로 배우는 실전 웹 서비스 개발 책에서는 domestic-updater.js 를 통해서 통계 데이터를 크롤링한 후, domestic-update.js를 통해서 변경된 내용만 코로나보드 API 서버로 전달하여 저장하는 내용까지 모두 다루고있습니다. 하지만 여기에서는 ‘자바스크립트로 크롤러 만들기’ 주제에 맞게 데이터를 크롤링하는 부분만 살펴보도록하겠습니다.
데이터 크롤링 코드 작성
01 페이지를 크롤링하는 DomesticCrawler 클래스의 기본 구성을 구현합니다.
crawler/domestic-crawler.js
const _ = require('lodash'); // 다양한 유틸리티 함수 제공
const axios = require('axios'); // HTTP 클라이언트 모듈
const cheerio = require('cheerio'); // HTML 파싱 및 DOM 생성
class DomesticCrawler {
constructor() {
this.client = axios.create({
// ❶ 실제 크롬 웹 브라우저에서 보내는 값과 동일하게 넣기
headers: {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
},
});
}
// ❷ 실제 크롤링을 수행
async crawlStat() {
// '발생동향 > 국내 발생 현황' 페이지의 주소
const url = 'https://yjiq150.github.io/coronaboard-crawling-sample/clone/ncov/';
const resp = await this.client.get(url);
const $ = cheerio.load(resp.data);
return {
// 확진자, 사망자, 격리해제, 검사중, 결과음성, 총 검사자 수
basicStats: this._extractBasicStats($),
byAge: this._extractByAge($), // 나이에 따른 확진자, 사망자 수
bySex: this._extractBySex($), // 성별에 따른 확진자, 사망자 수
};
}
_extractBasicStats() { ... 생략 ... }
_extractByAge() { ... 생략 ... }
_extractBySex() { ... 생략 ... }
// ❸ 텍스트로된 숫자를 실제 수치로 변환
_normalize(numberText) {
// 아래 형태로 들어올 때 괄호 없는 앞쪽 숫자만 추출
// ex) 8,757(45.14)
const matches = /[0-9,]+/.exec(numberText);
const absValue = matches[0];
return parseInt(absValue.replace(/[\s,]*/g, ''));
}
}
module.exports = DomesticCrawler;
먼저 axios.create() 함수를 실행해 HTTP 클라이언트를 생성합니다. ❶ User-Agent 헤더 정보를 바꿉니다. 실제 맥OS에서 동작하는 크롬 웹 브라우저에서 복사해온 겁니다. (이 값은 크롬 [개발자 도구]의 [Network] 탭을 열고 기록된 HTTP 요청을 클릭하여 요청 헤더 영역을 살펴봐서 확인할 수 있습니다.) 이렇게 실제 웹브라우저의 유저 에이전트를 넣어주는 이유는 웹 서버에 따라서는 일반적인 웹 브라우저가 아니면 접근을 허용하지 않거나 아예 다른 응답을 하는 경우가 종종 있기 때문입니다. 만약 여기서 유저 에이전트를 별도로 넣어주지 않는다면 ‘axios/0.21.1’ 형태가 기본값으로 들어갑니다.
❷ crawlStat() 함수는 메인 HTML 페이지를 로드하여 원하는 데이터를 추출합니다. 각 데이터별로 추출 함수를 만들었습니다. ❸ 정규표현식을 이용하여 텍스트로부터 숫자와 쉼표만 추출한 후, 공백과 쉼표는 제거하여 문자열이 아닌 숫자 타입으로 변환하는 유틸리티 함수입니다.
정규표현식이란?
정규표현식은 패턴 매칭을 이용하여 문자열에서 원하는 값만 추출하거나 삭제할 때 매우 유용한 도구입니다. 크롤링을 할 때 추출한 문자열 안에서 원하는 부분만 정확히 가져오고 싶은 경우 매우 편리하게 사용할 수 있습니다. 처음 접하는 분들에게는 사용법이 어려울 수 있으나 실무에서 매우 많이 사용되는 필수적이 도구 중 하나이니 꼭 익히는 것을 추천합니다. 정규표현식을 만들어 결과를 바로 확인하는 https://regex101.com/ 같은 웹사이트도 있으니 유용하게 활용하길 빕니다.
02 기본 정보를 추출하는 함수를 구현합시다.
_extractBasicStats() 함수 상세 내용
_extractBasicStats($) {
let result = null;
const titles = $('h5.s_title_in3');
titles.each((i, el) => {
// h5 태그 안에 텍스트(제목)와 span 태그(업데이트 날짜)가 섞여있는 경우가 존재
// ❶ 여기서 태그를 제외하고 순수 텍스트만 분리
const titleTextEl = $(el)
.contents() // 요소 서브의 텍스트 노드를 포함한 모든 노드를 반환
.toArray()
.filter((x) => x.type === 'text');
// 제목 '누적 검사현황' 다음에 나오는 테이블을 찾기
if ($(titleTextEl).text().trim() === '누적 검사현황') {
const tableEl = $(el).next();
if (!tableEl) {
throw new Error('table not found.');
}
// ❷ 테이블 내의 셀을 모두 찾아서 가져옴
const cellEls = tableEl.find('tbody tr td');
// 찾아진 셀에 있는 텍스트를 읽어서 숫자로 변환
const values = cellEls
.toArray()
.map((node) => this._normalize($(node).text()));
result = {
confirmed: values[3],
released: values[1],
death: values[2],
tested: values[5],
testing: values[6],
negative: values[4],
};
}
});
if (result == null) {
throw new Error('Data not found');
}
return result;
}
국내 발생 현황 페이지에서 ‘확진자, 사망자, 격리해제, 검사중, 결과음성, 총 검사자 수’ 데이터는 ‘누적 검사현황’ 제목 바로 아래에 있는 테이블에 들어 있습니다. 안타깝게도 이 페이지의 DOM을 자세히 살펴봐도 이 테이블만 정확히 특정하는 id값이나 class 속성 설정이 되어 있지 않습니다. 이런 경우에는 ‘누적 검사현황’ 제목을 가진 요소를 찾고, 해당 요소 다음에 인접하여 존재하는 테이블 요소를 찾아나가는 식으로 코드를 작성해야 합니다.
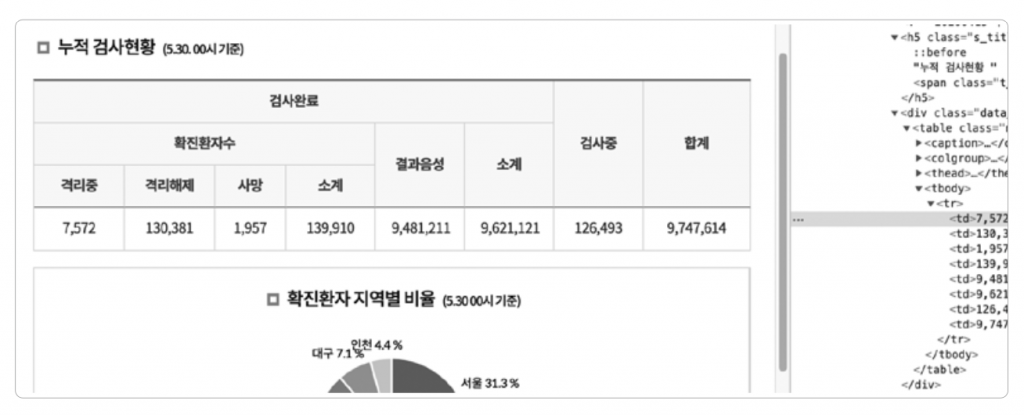
목표로 한 테이블을 찾고 나서 ❷ 해당 테이블 요소를 기준으로 다시 한번 CSS 셀렉터를 이용하여 찾습니다. 크롤링할 모든 데이터가 td 태그 안에 모두 있기 때문에 tbody tr td 셀렉터를 사용했습니다. 찾은 모든 셀에서 텍스트를 추출하고 해당 텍스트에 _normalize() 함수를 적용하여 정수 타입으로 변환합니다. 추출된 값들은 결과 객체에 필드별로 할당되어 반환됩니다.
03 성별, 연령별 확진자, 사망자 수를 추출하겠습니다. ❶ ‘확진자 성별 현황’, ❷ ‘확진자 연령별 현황’은 첫 번째 컬럼에 위치합니다. 두 테이블 모두에서 ❸ 두 번째 컬럼에 확진자, ➍ 네 번째 컬럼에 사망자 수가 위치합니다.
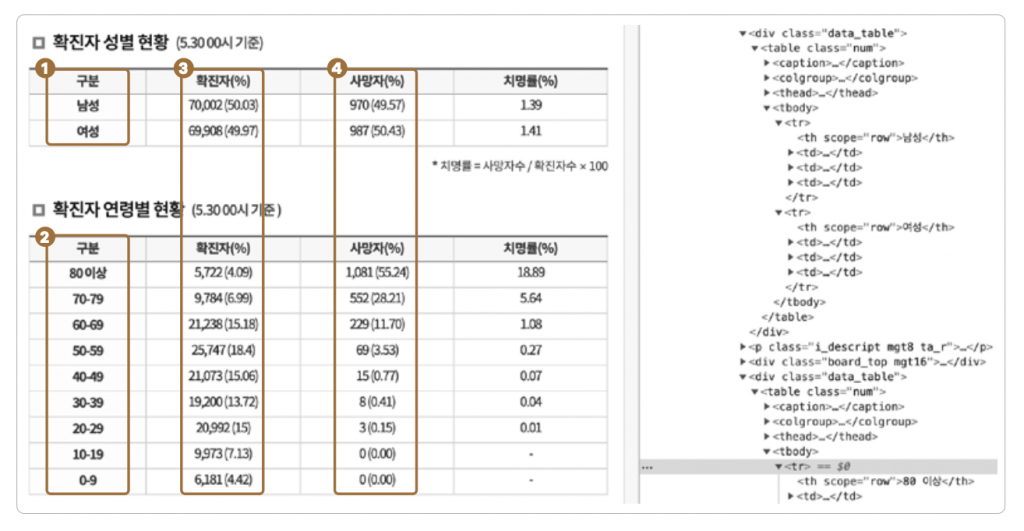
이 두 가지 테이블은 구조가 동일하기 때문에 ‘구분’ 컬럼을 기준으로 해당 행에 있는 데이터를 정확히 판단할 수 있습니다. 코드로 작성하면 다음과 같습니다.
_extractByAge(), _extractBySex() 함수 상세 내용
_extractByAge($) {
// '구분' 컬럼의 텍스트를 필드 이름으로 매핑
const mapping = {
'80 이상': '80',
'70-79': '70',
'60-69': '60',
'50-59': '50',
'40-49': '40',
'30-39': '30',
'20-29': '20',
'10-19': '10',
'0-9': '0',
};
return this._extractDataWithMapping(mapping, $);
}
_extractBySex($) {
const mapping = {
남성: 'male',
여성: 'female',
};
return this._extractDataWithMapping(mapping, $);
}
_extractDataWithMapping(mapping, $) {
const result = {};
$('.data_table table').each((i, el) => {
$(el)
.find('tbody tr')
.each((j, row) => {
const cols = $(row).children(); // 서브 요소를 모두 가져옴
_.forEach(mapping, (fieldName, firstColumnText) => {
// 현재 행의 첫 번째 컬럼값이 mapping에 정의된 이름과
// 동일한 경우에만 데이터 추출
if ($(cols.get(0)).text() === firstColumnText) {
result[fieldName] = {
confirmed: this._normalize($(cols.get(1)).text()),
death: this._normalize($(cols.get(2)).text()),
};
}
});
});
});
if (_.isEmpty(result)) {
throw new Error('data not found');
}
return result;
}
위 코드는 모든 테이블을 순회하면서, 각 테이블의 행을 의미하는 tr 태그를 또 순회합니다. 각 행의 첫 번째 컬럼값이 찾고자 하는 컬럼값과 동일하면 해당 행의 첫 번째 컬럼을 확진자 수로, 두 번째 컬럼을 사망자 수로 결과 객체의 필드에 저장합니다.
이제 DomesticCrawler 클래스가 완성되었습니다.
04 완성된 DomesticCrawler 클래스를 불러와서 실행할 수 있도록 index.js 파일을 만들고 다음과 같이 작성해보겠습니다.
crawler/index.js
const DomesticCrawler = require('./domestic-crawler.js');
async function main() {
try {
const domesticCrawler = new DomesticCrawler()
const result = await domesticCrawler.crawlStat()
console.log(result);
} catch (e) {
console.error(‘crawlStat failed’, e);
}
}
main();
작성이 완료되면 node index.js 명령어를 통해 크롤러를 실행합니다. 다음과 같이 크롤링된 결과가 출력되는 것을 확인 할 수 있습니다.
[출력 결과]
{
basicStats: {
confirmed: 143596,
released: 133763,
death: 1971,
tested: 9808790,
testing: 137164,
negative: 9665194
},
byAge: {
'0': { confirmed: 6321, death: 0 },
'10': { confirmed: 10216, death: 0 },
'20': { confirmed: 21481, death: 3 },
'30': { confirmed: 19693, death: 8 },
'40': { confirmed: 21590, death: 15 },
'50': { confirmed: 26295, death: 70 },
'60': { confirmed: 21590, death: 230 },
'70': { confirmed: 9898, death: 557 },
'80': { confirmed: 5768, death: 1086 }
},
bySex: {
male: { confirmed: 71544, death: 974 },
female: { confirmed: 71308, death: 995 }
}
}
마무리
이번 장에서는 실제 존재하는 웹사이트의 클론 사이트를 대상으로 크롤러를 만드는 방법을 알아봤습니다. 여기까지 따라오셨으면 이제 자바스크립트로 크롤러를 만드는데 어느정도 자신감이 생기셨을 것 입니다.
이렇게 만든 크롤러는 매번 수동으로 실행할 때 보다, 주기적으로 자동 실행될 때 더 큰 효용성을 가질 수 있습니다. 특히 맥OS나 리눅스같은 유닉스 계열 운영체제에서는 크론cron을 이용하여 손쉽게 스케줄링할 수 있기 때문에 꼭 자동화 해보시는 것을 추천합니다. 제가 집필한 책에서 AWS EC2를 이용하여 리눅스 서버 인스턴스를 생성하고 여기서 크론을 이용하여 크롤러를 주기적으로 수행하는 것 까지 모두 다루기 때문에 이것을 참고해주셔도 좋고, 검색 엔진에서 ‘크론’으로 찾아보더라도 자료들이 많으니 꼭 공부해보시길 바랍니다.
긴 튜토리얼 끝까지 읽어주셔서 감사합니다.
- 자바스크립트로 크롤러 만들기 소개: 크롤링 개념 및 튜토리얼 소개
- 자바스크립트로 크롤러 만들기 1편: 크롤링을 위한 크롬 개발자 도구 사용법 익히기
- 자바스크립트로 크롤러 만들기 2편: 웹페이지 크롤링을 위한 배경 지식 알아보기
- 자바스크립트로 크롤러 만들기 3편: 다양한 유형의 웹페이지 크롤러 만들어보기
- 자바스크립트로 크롤러 만들기 4편: 실제 웹페이지 크롤링해보기

‘코로나보드로 배우는 실전 웹 서비스 개발’ 책에서는 크롤러 뿐만 아니라 구글 스프레드 시트를 저장소로 사용하는 방법, 개츠비 + 리액트를 사용해서 웹사이트를 개발하는 방법, 도메인 설정, 검색엔진 최적화, 사용자 분석, 광고를 통한 수익화 등을 다룹니다. 웹서비스 개발과 운영에 대한 전반적인 내용을 알고싶으신 분들이나, 사이드 프로젝트를 만들어보고 싶으신 분들에게 추천합니다.