네이버, 카카오톡, 페이스북 등 다른 플랫폼을 통해 소셜 로그인을 하는 경우 사용자 이름 등에 이모지(emoji)나 특수문자가 붙어있는 경우들이 종종 있다. 이렇게 전달받은 사용자 이름을 그대로 사용하면 닉네임이 아닌 실제 이름을 입력해야하는 예약시스템 등과 연동할 때 특수문자로 인한 오류가 자주 발생한다.
이러한 오류를 피하기 위해서는 전달받은 이름에서 정규식을 통해 특수문자와 이모지를 걸러내는 것이 가장 일반적인 접근방식이다.
얼핏 생각해서 영어/한글 이름만 허용하고 공백을 제외한 나머지 특수문자를 걸러내려면 아래처럼 할 수 있겠다.
[가-힣a-zA-Z ]+국내용 서비스라면 이렇게만 해도 큰 문제가 없겠지만 다국어 지원이 안되기 떄문에 뭔가 찝찝한 기분이 든다. 한자, 일본어, 독일어, 스페인어 태국어 등의 영어 알파벳이 아닌 문자체계를 사용하는 여러 언어까지 지원하려면 어떻게 해야할까?
이경우 아래와 같은 Unicode Property 를 의미하는 정규식인 \p{…} 를 이용하여 매칭을 하면 편리하다. (참고: 소문자 p는 해당 프로퍼티를 매칭하겠다는 뜻이고, 대문자 P는 해당 프로퍼티가 아닌것 즉 p의 negation을 매칭할 때 사용할 수 있음)
아래 예시에서는 \p{L}을 이용하여 유니코드 글자(Letter)와 공백 만을 매칭한다.
[\p{L} ]+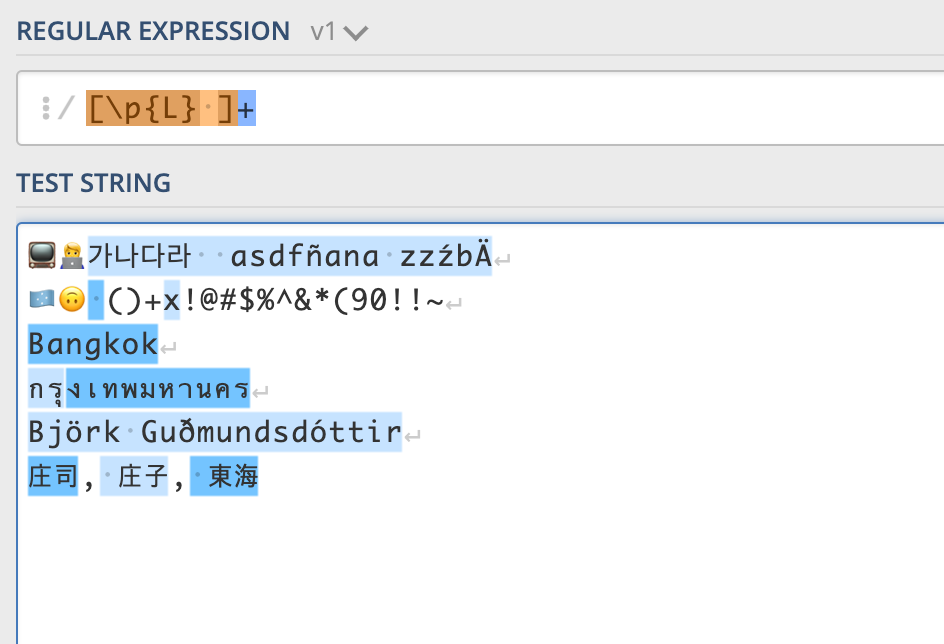
위 스크린샷은 https://regex101.com/ 사이트에서 직접 정규식을 테스트 해본 화면이다. 이 사이트에서는 매칭할 텍스트를 입력해두고 정규식을 바로바로 작성하면서 라이브로 매칭이 잘 되는지 테스트 해볼 수 있기 때문에 매우 유용하니 실무에 사용하면 편리하다.
참고로 Java, PHP에서는 위 정규식이 잘 지원되지만 아쉽게도 자바스크립트에서는 바로 지원이 되지 않기때문에 아래 별도의 라이브러리를 이용하여 해당 정규식을 사용할 수 있다.
https://github.com/slevithan/xregexp
더 많은 Unicode Property 종류에 대해서는 다음 링크를 참고하면 된다. https://www.regular-expressions.info/unicode.html#prop
다른 문자는 허용하되 텍스트에서 이모지만 삭제하고싶은 경우
js의 경우 아래 라이브러리를 사용하면 emoji가 매칭되는 정규식 패턴을 바로 얻을 수 있다.